Line Search Methods
Gradient descent
One of the simplest local optimisation algoriths is gradient descent. It is initialised at some point in parameter space , and at each iteration the function is reduced by following the direction of steepest descent
This is an example of an important class of algorithms called the line search methods. These algorithms choose a search direction at each iteration , and search along the 1D line from the initial point to a new point
with a lower function value. The problem at each iteration becomes a one-dimensional optimisation problem along to find the optimal value of . Each line search algorithm is thus defined on how it chooses both the search direction and the optimal .
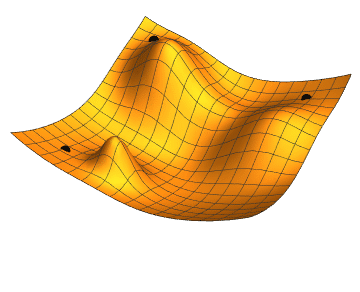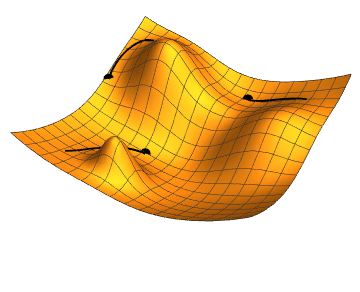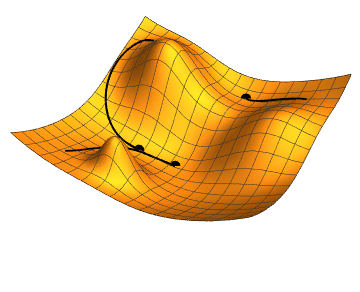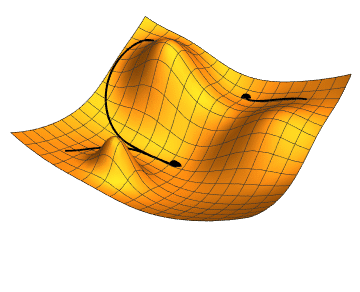
Plateaus with low gradient
An obvious downside to simple gradient descent can be seen for functions which have regions of zero or small gradients, or plateaus. Here a gradient descent algorithm with a constant will proceed very slowly, if at all. This motivates another important line search algorithm, Newtons method.
The Newtons direction can be derived by considering the second-order Taylor expansion of the function
We find the value of that minimises by setting the derivative of to zero, leading to
Unlike the steepest descent, Newtons method has a natural step length , which is suitable for a wide variety of problems and can quickly cross areas of low gradient. Naturally, since the algorithm is based on a second-order approximation of the function , it works better if this approximation is reasonably accurate.
Newtons method can be used as long as the inverse of the second derivative of the function , exists (e.g. it will always exist for a positive definite ). However, even when this inverse does exist it is possible that the direction does not satisfy the descent condition (or equivilently ), so many modifications to Newtons methods, falling under a class of methods called Quasi-Newton methods, have been proposed to satisfy this descent condition.
Quasi-Newton methods do not require the (often onerous) calculation of the hession like Newtons, instead they form an approximation to the hessian that is updated at each step using the information given by the gradient evaluations . Two popular methods of performing this update are the symmetric-rank-one (SR1), and the Broyden, Fletcher, Goldfarb, and Shanno, (BFGS) formula. Once the approximation is formed then the search direction is calculated via
For more details of other line search methods, please see Chapter 3 of the Nocedal and Wright textbook, or in the other textbooks listed at the end of this lesson. Finally, it should be noted that the conjugate gradient method can also be used for non-linear optimisation, where the search direction is given by
Step length
In line search methods, choosing the step length is a non-trivial task. Ideally we would want to chose to minimise the function along the one-dimensional search direction . That is, we wish to minimise
In general it is too expensive to do this minimisation exactly, so approximate methods are used so that multiple trial values are trialled, stopping when a candidate is found that satisfies a set of conditions. There are two main conditions used, the Wolfe conditions and the Goldstein conditions.
The two Wolfe conditions are the sufficient decrease condition, which ensures that the reduction in the function value is proportional to the step length and the gradient in the direction of the step
The second Wolfe condition is the curvature condition, which prevents unacceptibly short steps by ensuring that the slope of is greater than some constant times the initial slope
where . Typical values are and . The strong Wolfe conditions restrict the gradient to be small, so as to exclude points that are too far from stationary points of
The Goldstein conditions are similar in spirit to the Wolfe conditions, and are formed from the two inequalities
with . The first inequality prevents small step sizes while the second is the same sufficient decrease condition as in the Wolfe conditions. The Goldstein conditions are often used in Newton-type methods but for quasi-Newton methods the Wolfe conditions are prefered. The diagrams from the text by Nocedal and Wright illustrate the two conditions
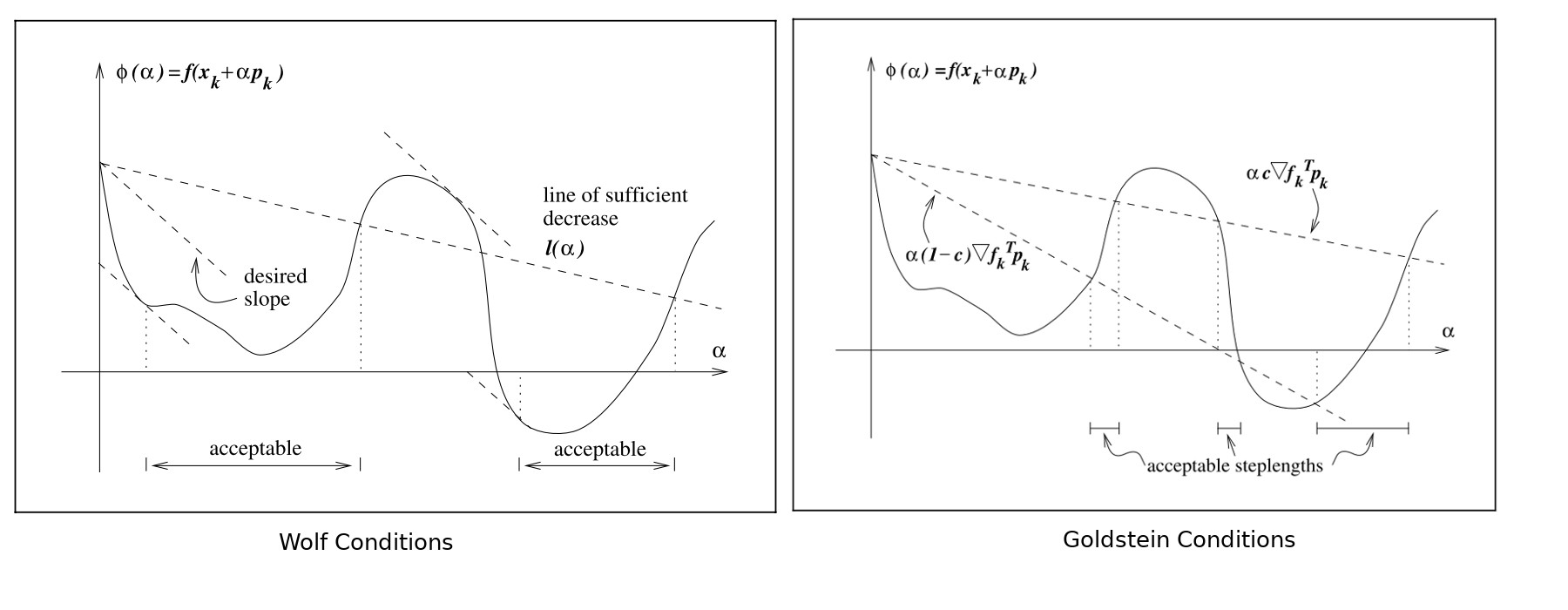
Algorithms for choosing candidate step size values can be complicated, so we will only mention here one of the simplest, which is the backtracking method. This approach implicitly satisfies the condition on too small , and only repeatedly test for the common sufficient decrease condition that appears in both the Wolfe and Goldstein condtitions.
Backtracking algorithm
Choose , ,
repeat until
end repeat.
Software
Scipy has a wide variety of (mostly) line search and trust region algorithms in
scipy.optimize. There are 14 local minimisers, so we won't list them all here!It is worth noting that Scipy includes the
line_searchfunction, which allows you to use their line search satisfying the strong Wolfe conditions with your own custom search direction.Scipy also includes a
HessianUpdateStrategy, which provides an interface for specifying an approximate Hessian for use in quasi-Newton methods, along with two implementationsBFGSandSR1.
Problems
Line Search Problems
Program the steepest descent and Newton algorithms using the backtracking line search. Use them to minimize the Rosenbrock function. Set the initial step length and print the step length used by each method at each iteration. First try the initial point and then the more difficult starting point .
Plot the function surface using
matplotliband overlay the line search segments so you can visualise the progress of your algorithm. Observe the difference between the algorithms when the gradient of the rosenbrock function is low (i.e. at the bottom of the curved valley)Repeat (1) and (2) above using the line search implemented in Scipy
scipy.optimize.line_search, which uses the strong Wolfe conditions.